第 6 章 主题模型
在文本挖掘中,我们经常有多个包含多个文档的集合,如博客或新闻文章,我们想将其自然分组,以便分开阅读。主题模型是对这样的文档进行无监督分类的一种方法,类似于数字型数据的聚类,即使不知道需要寻找什么也可以找到自然的组别。
隐含狄利克雷分布(Latent Dirichlet allocation,LDA)是一种特别流行的拟合主题模型的方法。它将每个文档视为多个主题的混合,而每个主题又是多个词的混合。LDA 允许文档在内容层面互有重合,而不是被分成离散的多个组,这在某种意义上体现了自然语言的典型用法。
图 6.1: 应用主题模型进行文本分析的流程图。
如图 6.1 所示,我们可以使用 tidy 文本原则得到主题模型,通过在全书中使用的同一套 tidy 工具。在本章中,我们将学习 topicmodels 包 (Grün and Hornik 2021) 中的 LDA 对象,特别是将这些模型 tidy 化,以便在 ggplot2 和 dplyr 中加以操作。我们还将探索一个多本书籍章节聚类的例子,从中可以看到主题模型能基于文本内容“学习”到不同的书有何不同。
6.1 隐含狄利克雷分布
隐含狄利克雷分布是主题模型最通行的算法之一。无需触及其模型背后的数学,我们可以从两个原则出发理解 LDA。
- 每个文档都是主题的混合 设想每个文档可能含有的词来自特定比例的几个主题。比如,针对一个双主题的模型,我们可以说“文档 1 是 90% 主题 A 和 10% 主题 B,而文档 2 是 30% 主题 A 和 70% 主题 B。”
- 每个主题都是词的混合 比如,可以设想一个美国新闻的双主题模型,一个主题是“政治”,一个是“娱乐”。政治主题中最常见的词可能是“总统”“议院”“政府”,而组成娱乐主题的词如“电影”“电视”“演员”。重要的是,词可以被主题共用,比如“预算”就可能同等地出现在两个主题中。
LDA 是同时估算这两件事的数学方法:找到与每个主题相关联的词的混合,同时确定描述每个文档的主题的混合。这个算法的实现已经有很多种,我们将深度探索其中之一。
在章 5 中我们简要地介绍了 topicmodels 包提供的 AssociatedPress 数据集作为 DocumentTermMatrix 的一个例子。这是一个2246篇新闻文章的集合,来自美国的一个通讯社,主要发表于1988年前后。
library(topicmodels)
data("AssociatedPress")
AssociatedPress## <<DocumentTermMatrix (documents: 2246, terms: 10473)>>
## Non-/sparse entries: 302031/23220327
## Sparsity : 99%
## Maximal term length: 18
## Weighting : term frequency (tf)我们可以使用 topicmodels 包中的 LDA() 函数,设定 k = 2 以创建一个双主题的 LDA 模型。
Almost any topic model in practice will use a larger k, but we will soon see that this analysis approach extends to a larger number of topics.
这个函数返回一个对象,包含拟合模型的全部细节,词如何与主题相关联,而主题如何与文档相关联。
# set a seed so that the output of the model is predictable
ap_lda <- LDA(AssociatedPress, k = 2, control = list(seed = 1234))
ap_lda## A LDA_VEM topic model with 2 topics.拟合模型比较简单,余下的分析将包括使用 tidytext 包探索和解释模型。
6.1.1 词-主题概率
在章 5 中我们介绍了 tidy() 方法,最初来自 broom 包 (Robinson, Hayes, and Couch 2021),可以将模型对象 tidy 化。tidytext 包提供这个方法从模型中提取每主题每词的概率,称为 \(\beta\)(beta)。
library(tidytext)
ap_topics <- tidy(ap_lda, matrix = "beta")
ap_topics## # A tibble: 20,946 x 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 aaron 1.69e-12
## 2 2 aaron 3.90e- 5
## 3 1 abandon 2.65e- 5
## 4 2 abandon 3.99e- 5
## 5 1 abandoned 1.39e- 4
## 6 2 abandoned 5.88e- 5
## 7 1 abandoning 2.45e-33
## 8 2 abandoning 2.34e- 5
## 9 1 abbott 2.13e- 6
## 10 2 abbott 2.97e- 5
## # ... with 20,936 more rows注意这把模型变成了一个主题每术语每行的格式。对于每个组合,模型计算了该术语来自该主题的概率。比如,术语 aaron 有 \(1.6869\times 10^{-12}\) 概率来自主题 1,而有 \(3.8959\times 10^{-5}\) 概率来自主题 2。
我们可以使用 dplyr 的 top_n() 列出每个主题最常见的10个术语。作为一个 tidy 数据框,这很容易由 ggplot2 可视化(图 6.2)。
ap_top_terms <- ap_topics %>%
group_by(topic) %>%
top_n(10, beta) %>%
ungroup() %>%
arrange(topic, -beta)
ap_top_terms %>%
mutate(term = reorder(term, beta)) %>%
ggplot(aes(term, beta, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
coord_flip()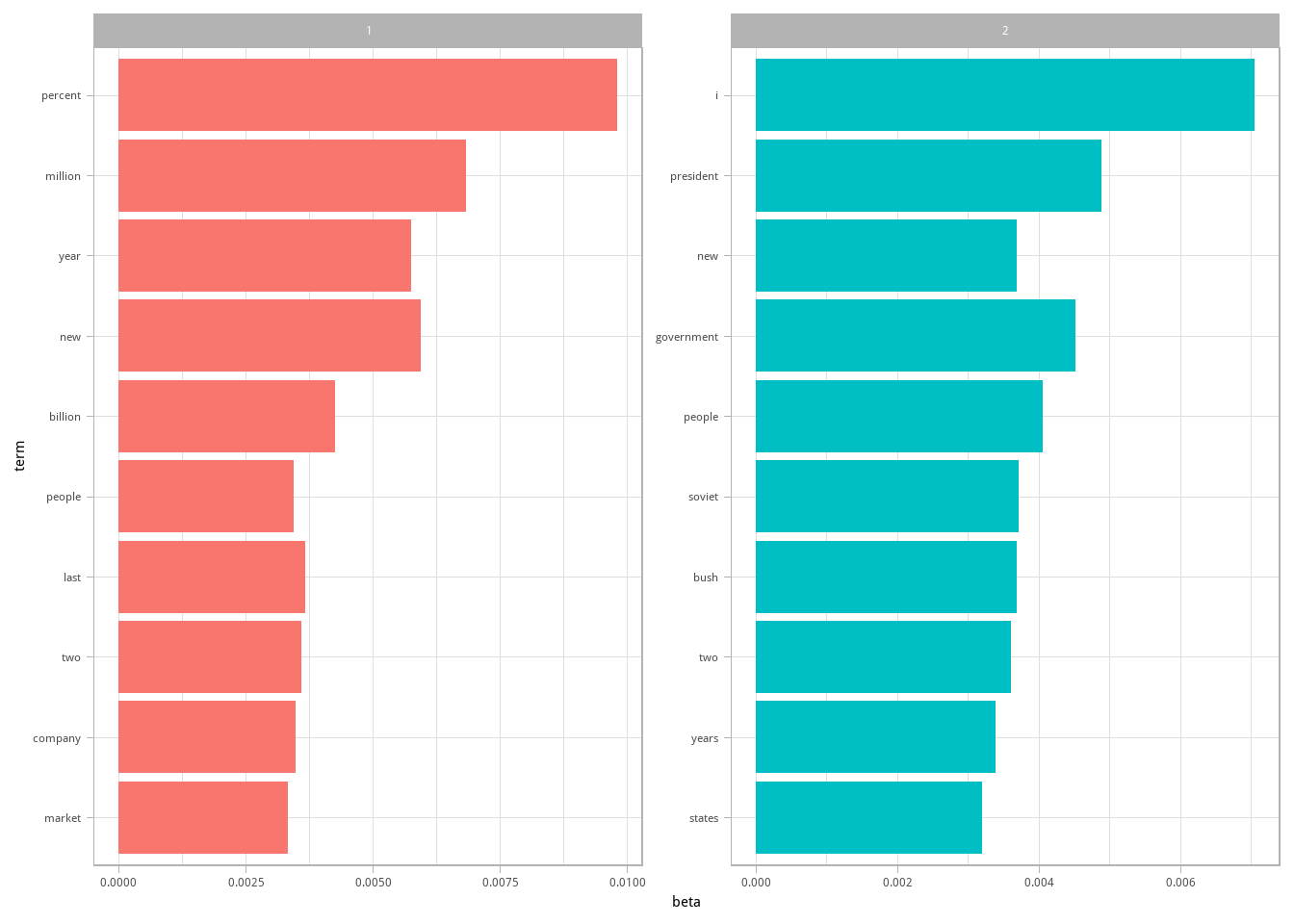
图 6.2: 每个主题中这些术语最常见
可视化可以帮助我们理解从文章中提取出的两个主题。主题1中最常见的词包括“percent”“million”“billion”“company”,提示可能代表了商业或金融新闻。主题2最常见的词有“president”“government”“soviet”,提示这个主题代表了政治新闻。一个重要的观察结果是两个主题中有相同的词,如“new”和“people”,在两个主题中都常见。这是主题模型相比“硬性聚类”方法的一个优点:使用自然语言的主题在用词上可能会有交叉。
另外,我们可以考虑 主题1和主题2间 \(\beta\) 有 最大距离 的术语。这可以通过对数比例估算:\(\log_2(\frac{\beta_2}{\beta_1})\) (对数比例可以使距离均匀化:两倍的 \(\beta_2\) 即对数比例1,而两倍 \(\beta_1\) 则是-1)。要限制为比较相关的词的集合,我们可以过滤相对常见的词,如在至少一个主题中 \(\beta\) 超过1/1000。
beta_spread <- ap_topics %>%
mutate(topic = paste0("topic", topic)) %>%
spread(topic, beta) %>%
filter(topic1 > .001 | topic2 > .001) %>%
mutate(log_ratio = log2(topic2 / topic1))
beta_spread## # A tibble: 198 x 4
## term topic1 topic2 log_ratio
## <chr> <dbl> <dbl> <dbl>
## 1 administration 0.000431 0.00138 1.68
## 2 ago 0.00107 0.000842 -0.339
## 3 agreement 0.000671 0.00104 0.630
## 4 aid 0.0000476 0.00105 4.46
## 5 air 0.00214 0.000297 -2.85
## 6 american 0.00203 0.00168 -0.270
## 7 analysts 0.00109 0.000000578 -10.9
## 8 area 0.00137 0.000231 -2.57
## 9 army 0.000262 0.00105 2.00
## 10 asked 0.000189 0.00156 3.05
## # ... with 188 more rows在两个主题中距离最大的词见图 6.3。
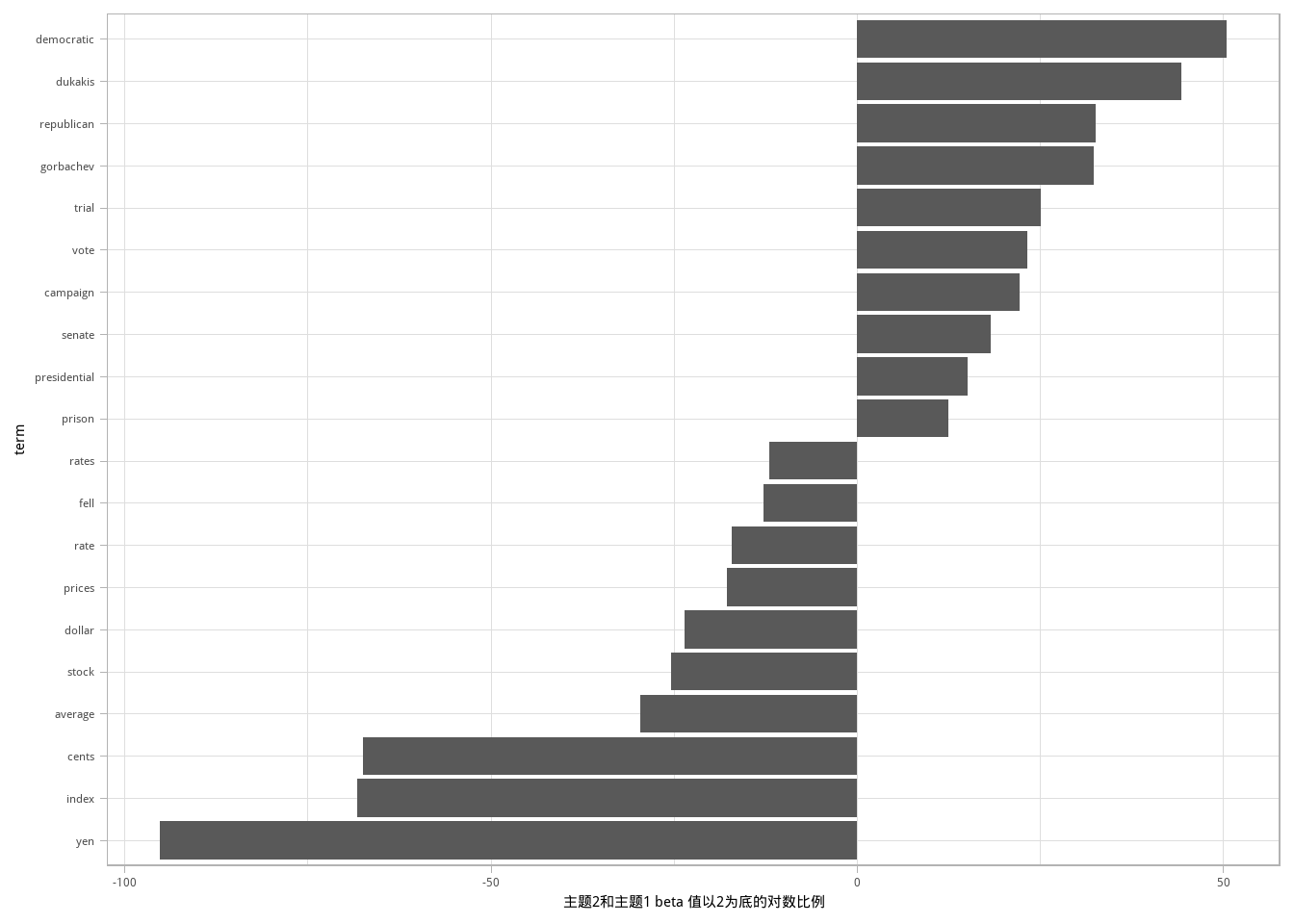
图 6.3: 主题2与主题1 \(\beta\) 差值最大的词
我们可以看到,主题2的常见词包括政党如“democratic”和“republican”,以及政治家的名字如“dukakis”和“gorbachev”。主题1的特征词更多的是货币如“yen”和“dollar”,还有金融术语如“index”“prices”和“rates”。这帮助我们进一步确认算法识别出的两个主题是政治和金融新闻。
6.1.2 文档-主题概率
除了按词的混合估计每个主题,LDA 也建立了作为主题混合的文档模型。我们检查一下每文档每主题的概率,称作 \(\gamma\)(gamma),作为 matrix = "gamma" 参数传给 tidy()。
ap_documents <- tidy(ap_lda, matrix = "gamma")
ap_documents## # A tibble: 4,492 x 3
## document topic gamma
## <int> <int> <dbl>
## 1 1 1 0.248
## 2 2 1 0.362
## 3 3 1 0.527
## 4 4 1 0.357
## 5 5 1 0.181
## 6 6 1 0.000588
## 7 7 1 0.773
## 8 8 1 0.00445
## 9 9 1 0.967
## 10 10 1 0.147
## # ... with 4,482 more rows这里的每一个值都是一个估算的来自该文档的词有多大比例来自该主题。比如,模型估算文档 1 中大约 0.2481 的词来自主题 1。
我们可以看到这些文档中很多都是两个主题的混合,但文档6几乎全部来自主题2,来自主题1的 \(\gamma\) 接近0。要检验这个答案,我们可以 tidy() 其文档-术语矩阵(见章 5.1)并检查该文档中最常见的词。
tidy(AssociatedPress) %>%
filter(document == 6) %>%
arrange(desc(count))## # A tibble: 287 x 3
## document term count
## <int> <chr> <dbl>
## 1 6 noriega 16
## 2 6 panama 12
## 3 6 jackson 6
## 4 6 powell 6
## 5 6 administration 5
## 6 6 economic 5
## 7 6 general 5
## 8 6 i 5
## 9 6 panamanian 5
## 10 6 american 4
## # ... with 277 more rows基于最常见的词,看起来这篇文章是关于美国政府与巴拿马当时的统治者 Noriega 的,这意味着算法正确地把它分在了主题2中(政治新闻)。
6.2 例:图书馆大捣乱
要检查一个统计方法,很有用的办法是在一个很简单的例子上尝试使用,而且你知道“正确答案”。比如,我们可以收集一组文档,恰好属于6个相互分离的主题,然后运行主题模型,看看算法能否正确区分出6个组。这可以让我们确认方法是有效的,并且感知到其如何运作,何时又会失效。我们用来自古典文学的一些数据进行尝试。
假设有个强盗闯入你的书斋,把几大名著及其(非原作者的)续作撕破了:
- 《水滸傳》《水滸後傳》
- 《西遊記》《後西游記》
- 《紅樓夢》《補紅樓夢》
这个强盗把书沿章回的边缘撕开堆成了一堆。我们怎么才能把这些杂乱的章节按原书整理好呢?这个问题具有挑战性,因为每个单章都 无标注:我们不知道什么词可以用来分组。因此我们使用主题模型来发现章如何聚类为可分辨的主题,每个主题(想必)就代表一本书。
我们用章 3 中介绍的 gutenbergr 包获取文本。
titles <- c("水滸傳", "西遊記", "紅樓夢",
"水滸後傳", "後西游記", "補紅樓夢")library(gutenbergr)
books <- gutenberg_works(title %in% titles, languages = 'zh') %>%
gutenberg_download(meta_fields = "title")作为预处理,我们把每部小说都按回分开,再用 tidytext 的 unnest_tokens() 分成每词一行。不幸的是,汉语分词的结果对最终模型影响很大,在不同系统或版本上可能会得到不甚一致的结论,有时差异还非常大。我们把每回当作独立的“文档”,命名为类似 紅樓夢_1 或 水滸傳_11 这样。在其它应用中,每个文档可以是一篇报纸上的文章,或者博客上的一篇博文。
library(stringr)
# 移除停止词,也可尝试不移除或调整停止词列表以适应文档特性
cutter <- worker(bylines = TRUE, stop_word = "data/stop_word_zh.utf8")
# 分成文档,每个文档为一回(章)
by_chapter <- books %>%
group_by(title) %>%
mutate(text = sapply(segment(text, cutter), function(x){paste(x, collapse = " ")})) %>%
mutate(chapter = cumsum(str_detect(text, "^第[零一二三四五六七八九十百 ]+回"))) %>%
ungroup() %>%
filter(chapter > 0) %>%
unite(document, title, chapter)
# 按词切分
by_chapter_word <- by_chapter %>%
unnest_tokens(word, text)
# 获得文档-词计数
word_counts <- by_chapter_word %>%
count(document, word, sort = TRUE) %>%
ungroup()
word_counts## # A tibble: 559,204 x 3
## document word n
## <chr> <chr> <int>
## 1 水滸傳_23 道 333
## 2 水滸傳_42 李 178
## 3 後西游記_5 惡 170
## 4 西遊記_33 道 166
## 5 紅樓夢_41 道 158
## 6 紅樓夢_70 儿 157
## 7 水滸傳_23 大 157
## 8 水滸傳_1 進 154
## 9 水滸傳_23 來 153
## 10 水滸傳_23 裏 152
## # ... with 559,194 more rows6.2.1 按章得到 LDA
现在我们的 word_counts 数据框为 tidy 形式,每行每文档一个术语,但 topicmodels 包需要一个 DocumentTermMatrix。如在章 5.2 中所叙述的,我们可以用 tidytext 的 cast_dtm() 把一个每行一个符号的表格映射为 DocumentTermMatrix。
chapters_dtm <- word_counts %>%
cast_dtm(document, word, n)
chapters_dtm## <<DocumentTermMatrix (documents: 400, terms: 34186)>>
## Non-/sparse entries: 559204/13115196
## Sparsity : 96%
## Maximal term length: 5
## Weighting : term frequency (tf)然后即可使用 LDA() 函数创建一个六主题模型。在这个例子里我们知道要寻找6个主题,因为有6本书;在其它问题里可以尝试几个不同的 k 值以找到比较合适的。有意思的是,对于本数据集三主题也很准确,但那三本并不精彩的续书就要分别和其原著混起来了!作为练习,读者可以自己尝试。
chapters_lda <- LDA(chapters_dtm, k = 6, control = list(seed = 1234))
chapters_lda## A LDA_VEM topic model with 6 topics.就像对 Associated Press 数据所做的一样,我们可以查看每主题每词概率。
chapter_topics <- tidy(chapters_lda, matrix = "beta")
chapter_topics## # A tibble: 205,116 x 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 道 0.0234
## 2 2 道 0.0181
## 3 3 道 0.0170
## 4 4 道 0.0246
## 5 5 道 0.0158
## 6 6 道 0.0239
## 7 1 李 0.000202
## 8 2 李 0.00398
## 9 3 李 0.00539
## 10 4 李 0.000186
## # ... with 205,106 more rows注意,这将模型变成了每行术语每术语一个主题的格式。对于每个组合,模型计算了该术语来自该主题的概率。比如,术语“道”在主题2中的概率有0.0181。
我们可以用 dplyr 的 top_n() 得到每个主题概率最高的术语。
top_terms <- chapter_topics %>%
group_by(topic) %>%
top_n(5, beta) %>%
ungroup() %>%
arrange(topic, -beta)
top_terms## # A tibble: 30 x 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 道 0.0234
## 2 1 行者 0.0100
## 3 1 是 0.00988
## 4 1 來 0.00755
## 5 1 有 0.00742
## 6 2 道 0.0181
## 7 2 來 0.0120
## 8 2 裏 0.0107
## 9 2 去 0.00986
## 10 2 人 0.00915
## # ... with 20 more rows这个 tidy 输出可直接进行 ggplot2 可视化(图 6.4)。
top_terms %>%
mutate(term = reorder(term, beta)) %>%
ggplot(aes(term, beta, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
coord_flip()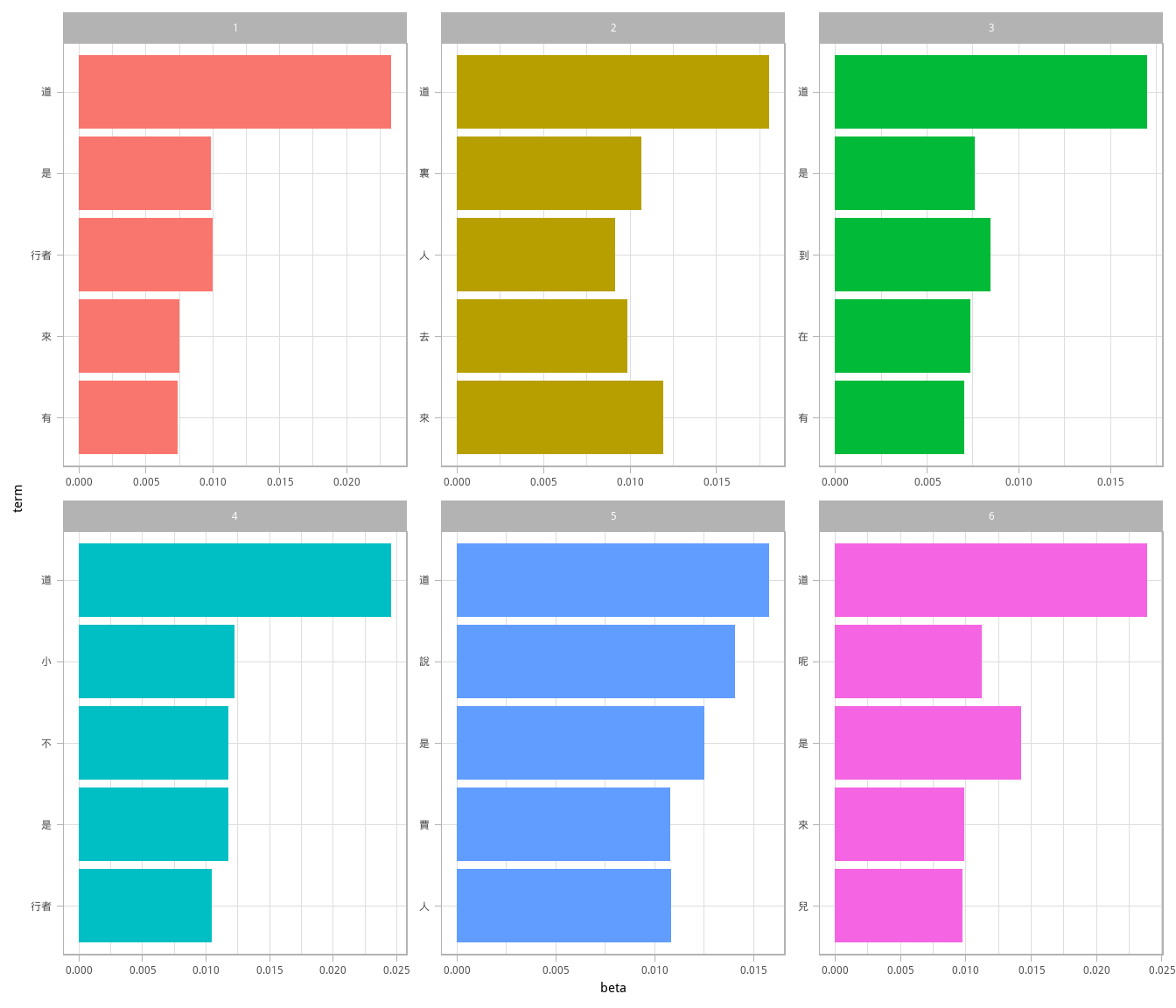
图 6.4: 每个主题中最常见的术语
有些主题很清晰地与不同书联系了起来!“賈”属于《紅樓夢》,“行者”应该属于《西遊記》等。我们还可注意到,既然 LDA 属于“模糊聚类”方法,有些词为多个主题共有,如“道”“有”“人”等。
6.2.2 按文档分类
此分析中的每个文档都表示了一个单章。因此,我们可能想要知道每个文档关联哪个主题。我们能把章放回到正确的书里吗?我们可以查看每主题每文档概率,\(\gamma\)(gamma)。
chapters_gamma <- tidy(chapters_lda, matrix = "gamma")
chapters_gamma## # A tibble: 2,400 x 3
## document topic gamma
## <chr> <int> <dbl>
## 1 水滸傳_23 1 0.00000316
## 2 水滸傳_42 1 0.00754
## 3 後西游記_5 1 0.00000598
## 4 西遊記_33 1 0.862
## 5 紅樓夢_41 1 0.00000606
## 6 紅樓夢_70 1 0.00000621
## 7 水滸傳_1 1 0.00164
## 8 西遊記_14 1 0.849
## 9 西遊記_47 1 0.869
## 10 紅樓夢_56 1 0.00000640
## # ... with 2,390 more rows每个值都是来自该文档的词属于该主题的估测比例。
现在有了主题概率,可以看看我们的无监督学习区分6本书的表现如何。我们预期一本书中的每章基本(或全部)出现在生成的对应主题中。
首先我们再把文档名拆分成书名与章回,然后绘制每主题每文档概率图 6.5。
chapters_gamma <- chapters_gamma %>%
separate(document, c("title", "chapter"), sep = "_", convert = TRUE)
chapters_gamma## # A tibble: 2,400 x 4
## title chapter topic gamma
## <chr> <int> <int> <dbl>
## 1 水滸傳 23 1 0.00000316
## 2 水滸傳 42 1 0.00754
## 3 後西游記 5 1 0.00000598
## 4 西遊記 33 1 0.862
## 5 紅樓夢 41 1 0.00000606
## 6 紅樓夢 70 1 0.00000621
## 7 水滸傳 1 1 0.00164
## 8 西遊記 14 1 0.849
## 9 西遊記 47 1 0.869
## 10 紅樓夢 56 1 0.00000640
## # ... with 2,390 more rows# reorder titles in order of topic 1, topic 2, etc before plotting
chapters_gamma %>%
mutate(title = reorder(title, gamma * topic)) %>%
ggplot(aes(factor(topic), gamma)) +
geom_boxplot() +
facet_wrap(~ title)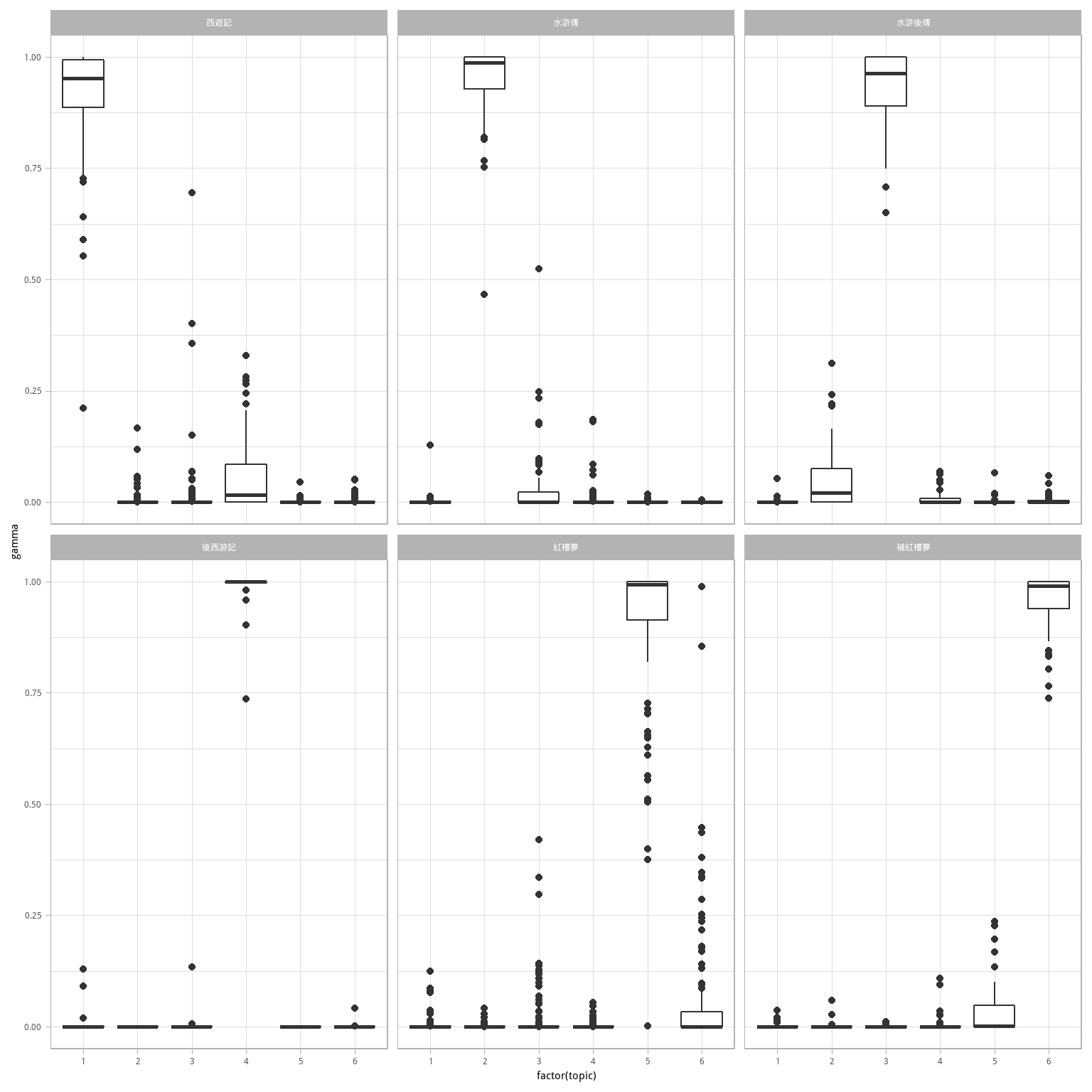
图 6.5: 每本书中每章的 \(\gamma\) 概率
注意,看起来每本书的多数章都被识别为唯一的单个主题;同时,续作与原著有一定相似性。有没有哪个章节被识别到另一本书?首先我们用 top_n() 找到每章被关联最多的主题,即该章的“分类”。
chapter_classifications <- chapters_gamma %>%
group_by(title, chapter) %>%
top_n(1, gamma) %>%
ungroup()
chapter_classifications## # A tibble: 400 x 4
## title chapter topic gamma
## <chr> <int> <int> <dbl>
## 1 西遊記 33 1 0.862
## 2 西遊記 14 1 0.849
## 3 西遊記 47 1 0.869
## 4 西遊記 34 1 0.841
## 5 西遊記 38 1 0.917
## 6 西遊記 56 1 0.761
## 7 西遊記 32 1 0.734
## 8 西遊記 44 1 0.929
## 9 西遊記 46 1 0.943
## 10 西遊記 24 1 0.932
## # ... with 390 more rows之后可以与每本书的“共识”主题进行比较(该书各章最多见的主题),看看哪些最常被误识别。
book_topics <- chapter_classifications %>%
count(title, topic) %>%
group_by(title) %>%
top_n(1, n) %>%
ungroup() %>%
transmute(consensus = title, topic)
chapter_classifications %>%
inner_join(book_topics, by = "topic") %>%
filter(title != consensus)## # A tibble: 5 x 5
## title chapter topic gamma consensus
## <chr> <int> <int> <dbl> <chr>
## 1 水滸傳 70 3 0.524 水滸後傳
## 2 西遊記 9 3 0.695 水滸後傳
## 3 紅樓夢 1 3 0.420 水滸後傳
## 4 紅樓夢 47 6 0.989 補紅樓夢
## 5 紅樓夢 5 6 0.854 補紅樓夢可以看到400章中只有几章识别错误,这个结果不算差。考虑到续作与原著的相似性,我们只挑出完全识别错的书。
library(stringi)
chapter_classifications %>%
inner_join(book_topics, by = "topic") %>%
filter(str_sub(title, -1, -1) != str_sub(consensus, -1, -1))## # A tibble: 2 x 5
## title chapter topic gamma consensus
## <chr> <int> <int> <dbl> <chr>
## 1 西遊記 9 3 0.695 水滸後傳
## 2 紅樓夢 1 3 0.420 水滸後傳只剩两个章节,如《紅樓夢》第一回情节散漫,并无特定主题。
6.2.3 词的分配:augment
LDA 算法的一步是将每个文档里的每个词分配给一个主题。一个文档里越多词被分配给该主题,一般来说在文档-主题分类中的权重(gamma)就越高。
我们可能想要取出原始的文档-词对,找出每个文档里的哪些词分配到了哪个主题。这是 augment() 函数的功能,也来自 broom 包,也是 tidy 化模型输出的一部分。tidy() 获取模型的统计组件,augment() 使用模型在原始数据的每个观察上添加信息。
assignments <- augment(chapters_lda, data = chapters_dtm)
assignments## # A tibble: 559,204 x 4
## document term count .topic
## <chr> <chr> <dbl> <dbl>
## 1 水滸傳_23 道 333 2
## 2 水滸傳_42 道 116 2
## 3 後西游記_5 道 124 4
## 4 西遊記_33 道 166 1
## 5 紅樓夢_41 道 158 5
## 6 紅樓夢_70 道 100 5
## 7 水滸傳_1 道 136 2
## 8 西遊記_14 道 152 1
## 9 西遊記_47 道 152 1
## 10 紅樓夢_56 道 36 5
## # ... with 559,194 more rows这返回书-术语计数的 tidy 数据框,但额外加了一列:.topic,每个文档中每个术语所分配的主题。(augment 添加的额外列总以 . 开头,以避免覆盖已有的列)。我们可以把共识书名与此 assignments 表格结合,找出未正确分类的词。
assignments <- assignments %>%
separate(document, c("title", "chapter"), sep = "_", convert = TRUE) %>%
inner_join(book_topics, by = c(".topic" = "topic"))
assignments## # A tibble: 559,204 x 6
## title chapter term count .topic consensus
## <chr> <int> <chr> <dbl> <dbl> <chr>
## 1 水滸傳 23 道 333 2 水滸傳
## 2 水滸傳 42 道 116 2 水滸傳
## 3 後西游記 5 道 124 4 後西游記
## 4 西遊記 33 道 166 1 西遊記
## 5 紅樓夢 41 道 158 5 紅樓夢
## 6 紅樓夢 70 道 100 5 紅樓夢
## 7 水滸傳 1 道 136 2 水滸傳
## 8 西遊記 14 道 152 1 西遊記
## 9 西遊記 47 道 152 1 西遊記
## 10 紅樓夢 56 道 36 5 紅樓夢
## # ... with 559,194 more rows这个真实书名(title)和被分配的书名(consensus)的组合对进一步探索很有用。例如我们可以绘制 混淆矩阵,显示一本书里的词有多经常被分配给另一本,使用 dplyr 的 count() 和 ggplot2 的 geom_tile(图 6.6。
assignments %>%
count(title, consensus, wt = count) %>%
group_by(title) %>%
mutate(percent = n / sum(n)) %>%
ggplot(aes(consensus, title, fill = percent)) +
geom_tile() +
scale_fill_gradient2(high = "red", label = percent_format()) +
theme_minimal() +
labs(x = "词被分配到的书",
y = "词来自的书",
fill = "正确分配的百分比") +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
panel.grid = element_blank(),
text = element_text(family = "wqy-microhei"))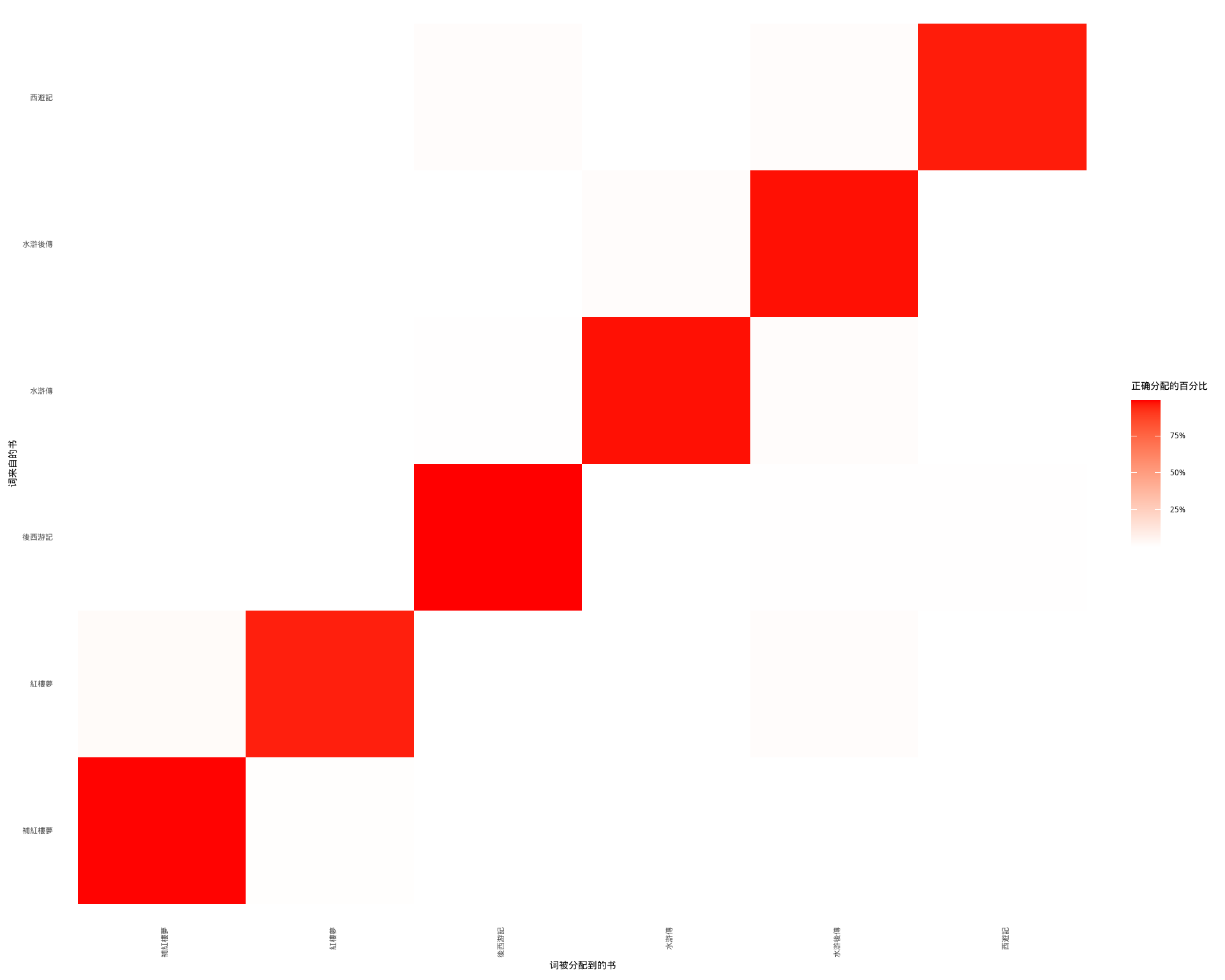
图 6.6: 展示 LDA 对每本书中的词进行分配的混淆矩阵。表格的每行代表词来自原书,每列代表被分配的书。
注意到几乎所有词都正确分配了,但不少书里的词都倾向于了《水滸後傳》。最常出错的词有哪些?
library(stringi)
wrong_words <- assignments %>%
filter(str_sub(title, -1, -1) != str_sub(consensus, -1, -1))
wrong_words %>%
count(title, consensus, term, wt = count) %>%
ungroup() %>%
arrange(desc(n))## # A tibble: 6,399 x 4
## title consensus term n
## <chr> <chr> <chr> <dbl>
## 1 紅樓夢 水滸後傳 之 116
## 2 水滸傳 後西游記 長老 105
## 3 水滸傳 後西游記 和尚 92
## 4 西遊記 水滸後傳 道 76
## 5 紅樓夢 水滸後傳 此 67
## 6 水滸傳 後西游記 行者 67
## 7 西遊記 水滸後傳 李 65
## 8 西遊記 水滸後傳 人 64
## 9 西遊記 水滸後傳 劉 62
## 10 水滸傳 後西游記 僧 58
## # ... with 6,389 more rows这里我们不看原著与续作互相混淆的词。長老、和尚、行者等称呼在多部书中都出现不少,错误分配可以理解。
另外,有可能有的词在一本书中从未出现过但仍然被分配给该书。如“礙於”只见于《後西游記》一次,却被分配给了《水滸後傳》。
word_counts %>%
filter(word == "礙於")## # A tibble: 1 x 3
## document word n
## <chr> <chr> <int>
## 1 後西游記_19 礙於 1LDA 算法有一定随意性,有可能把一个主题覆盖到多本书。
6.3 另一种 LDA 实现
topicmodels 包中的 LDA() 函数只是隐含狄利克雷分布分配算法的一种实现。例如 mallet 包 (Mimno 2013) 就实现了对 MALLET Java 文本分类工具包的包装,tidytext 包也提供了对这种模型的输出的 tidy 化工具。如果无法正常调用 library(mallet) (主要原因是其 rJava 依赖),可以尝试在终端中运行 R CMD javareconf,成功后重新打开 RStudio。
mallet 包采用了不太一样的输入格式。比如输入未经符号化的文档并自行符号化,且需要一个单独的停止词文件。这意味着我们在运行 LDA 之前需要把每个文档的文本都合并成一个字符串。
library(mallet)
# create a vector with one string per chapter
collapsed <- by_chapter_word %>%
anti_join(stop_words, by = "word") %>%
mutate(word = str_replace(word, "'", "")) %>%
group_by(document) %>%
summarize(text = paste(word, collapse = " "))
# create an empty file of "stopwords"
file.create(empty_file <- tempfile())
docs <- mallet.import(collapsed$document, collapsed$text, empty_file)
mallet_model <- MalletLDA(num.topics = 4)
mallet_model$loadDocuments(docs)
mallet_model$train(100)然而,模型创建后我们就可以像本章其它部分一样以几乎一致的方式使用 tidy() 和 augment() 函数。包括提取每个主题中词或每个文档中主题的概率。
# word-topic pairs
tidy(mallet_model)
# document-topic pairs
tidy(mallet_model, matrix = "gamma")
# column needs to be named "term" for "augment"
term_counts <- rename(word_counts, term = word)
augment(mallet_model, term_counts)可以以同样的方式用 ggplot2 探索和绘制 LDA 输出的模型。
6.4 小结
本章介绍了主题模型,用于寻找对一组文档具有代表性的词的聚类,展示了 tidy() 功能如何帮我们使用 dplyr 和 ggplot2 探索和理解这些模型。这是用 tidy 方法探索模型的一个优势:输出格式不同的挑战可由 tidy 化的函数处理,我们可以用一组标准工具探索模型的结果。特别地,我们看到主题模型能够把来自4本分立的书混合的章节拆分并识别,也探索了模型的局限性,找到了错误分配的词等。