第 1 章 tidy 文本格式
处理数据的 tidy 数据原则简单有效,用于文本也一样。按 Hadley Wickham (Wickham 2014) 的阐述,tidy 数据有如下特定的结构:
- 每个 variable 一列
- 每个 observation 一行
- 每种 observational unit 一个表格
于是,我们不妨定义 tidy 文本格式为一个 每行一个符号的表格。一个符号(token)是文本的一个有意义的单元,比如我们在分析中经常使用的词,而符号化(tokenization)就是将文本切分为符号的过程。这种“每行一个符号”的结构与当下分析中常用的其它文本存储方式形成鲜明对比,如字符串或者文档-术语矩阵。用于 tidy 文本挖掘时,存储在每行的 符号 通常是单个词,但也可以是 n元语(n-gram)、句或段落。在 tidytext 包里提供了符号化(tokenize)这些常见单元的方法,将其转换至“每项一行”的格式。
Tidy 数据集可以使用一组标准的 “tidy” 工具进行操作,包括了流行的包如 dplyr (Wickham et al. 2021)、tidyr (Wickham 2021)、ggplot2 (Wickham et al. 2020) 和 broom (Robinson, Hayes, and Couch 2021)。若能保持输入和输出均为 tidy 表格,用户可以在这些包之间自如转换。我们发现这些 tidy 工具可以自然地拓展到很多文本分析和探索活动中。
与此同时,tidytext 包并不强制用户在一次分析中全程保持文本数据为 tidy 形式,而是包含了 tidy() 多种对象的函数(见 broom 包),可以来自流行的文本挖掘 R 包,如 tm (Feinerer, Hornik, and Meyer 2008) 和 quanteda (Benoit et al. 2020)。这使得类似如下的工作流成为可能:使用 dplyr 和其它 tidy 工具对数据进行导入、过滤和处理,之后转换为文档-术语矩阵进行机器学习,所得到的模型可以再被转换回 tidy 形式供解读并由 ggplot2 视觉化。
1.1 tidy 文本与其它数据结构的对比
如前所述,我们定义 tidy 文本格式为一个表格,每行一个符号。以这种方式结构化的文本数据遵循 tidy 数据原则,可以用统一一致的工具进行操作。这值得和文本挖掘方法中常用的其它存储文本的格式进行对比。
- 字符串:文本当然可以用字符串存储,也就是 R 中的字符向量,这种形式的文本数据一般会先读进内存。
- 语料:这些种类的典型对象包含了原始的字符串,并带有额外的元数据和细节标注等。
- 文档-术语矩阵:这是一个稀疏矩阵,描述了文档的一个集合(即一组语料),每个文档一行,每个术语一列。矩阵中的典型数据为词的个数或 tf-idf(见章 3)。
暂时先不探索语料和文档-术语矩阵对象,章 5 将会讲到。这里我们从将文本转换成 tidy 格式的基础开始。
1.2 unnest_tokens 函数
这里选取李白的《静夜思》作为中文的例子。
text <- c("床前明月光,",
"疑是地上霜。",
"举头望明月,",
"低头思故乡。")
text## [1] "\u5e8a\u524d\u660e\u6708\u5149," "\u7591\u662f\u5730\u4e0a\u971c。"
## [3] "\u4e3e\u5934\u671b\u660e\u6708," "\u4f4e\u5934\u601d\u6545\u4e61。"中文一般不用空格隔开词,所以需要完成分词的步骤(出于各种原因,分词结果并不总是准确)。这里选择 jiebaR (Wenfeng and Yanyi 2019),内置了多种分词方式并直接支持停止词等。
library(jiebaR)
# 保留标点符号
cutter <- worker(bylines = TRUE, symbol = TRUE)
text_wb <- sapply(segment(text, cutter), function(x){
paste(x, collapse = " ")})
text_wb## [1] "\u5e8a\u524d \u660e\u6708\u5149 ," "\u7591\u662f \u5730\u4e0a \u971c 。"
## [3] "\u4e3e\u5934 \u671b\u660e\u6708 ," "\u4f4e\u5934 \u601d \u6545\u4e61 。"我们想要分析的是个典型的字符向量。要把它变成 tidy 文本数据集,我们先要把它放进数据框。
library(dplyr)
text_df <- tibble(line = 1:4, text = text_wb)
text_df## # A tibble: 4 x 2
## line text
## <int> <chr>
## 1 1 床前 明月光 ,
## 2 2 疑是 地上 霜 。
## 3 3 举头 望明月 ,
## 4 4 低头 思 故乡 。这个数据框显示为”tibble“是什么意思?一个 tibble 是 R 里一个现代的数据框类,在 dplyr 和 tibble 包中可用,它有个方便的打印方法,不把字符串转换为因子,也不为行命名。Tibble 特别适用于 tidy 工具。
注意,这个包含文本的数据框尚未兼容 tidy 文本分析。我们不能过滤出词,也不能计数哪些出现更频繁,因为每行都由多个词合并组成。我们需要把它转换成 每行每文档一个符号。
A token is a meaningful unit of text, most often a word, that we are interested in using for further analysis, and tokenization is the process of splitting text into tokens.
在第一个例子里,我们只有一个文档(一首诗),不过我们马上就会探索多个文档的例子。
在我们的 tidy 文本框架中,我们需要把文本拆分成独个的符号(这个过程叫做 符号化)并且 将之变形为 tidy 数据结构。要做到这些,可以使用 tidytext 的 unnest_tokens() 函数。特意为中文用户解释一下词源,un-nest 即 nest 的反向操作:把内容从 nest 里取出来。
library(tidytext)
text_df %>%
unnest_tokens(word, text)## # A tibble: 14 x 2
## line word
## <int> <chr>
## 1 1 床
## 2 1 前
## 3 1 明
## 4 1 月光
## 5 2 疑
## 6 2 是
## 7 2 地上
## 8 2 霜
## 9 3 举头
## 10 3 望
## # ... with 4 more rows这里用到 unnest_tokens 的两个基本参数是列名。首先是将要创建的输出的列名,文本将被拆分到这里面(在这个例子里是 word),然后是输入的列名,文本来自于此(在这个例子里是 text)。回忆一下,上面的 text_df 叫做 text 的列包含了所需的数据。
用过 unnest_tokens 之后,我们把每行拆分了,于是现在新的数据框里每行有一个符号(词);正如所见,unnest_tokens() 默认按单个词进行符号化。还需要注意:
- 其它列原样保留,比如每个词来自的行的行号。
- 标点会被去掉。
- 默认情况下,
unnest_tokens()把符号转换为小写字符,这是为了更方便与其它数据集比较或合并(用to_lower = FALSE参数可关闭这个行为)。
有了这种格式的数据,我们可以使用标准的 tidy 工具套装进行操作、处理和可视化,即 dplyr、tidyr 和 ggplot2。如图 1.1 所示。

图 1.1: 使用 tidy 数据原则进行文本分析的典型流程图
1.3 用 tidy 处理名著
英文的例子可使用 janeaustenr (Silge 2017) 引入 Jane Austen 的六部完整已发表小说的文本,并可转换为 tidy 格式。janeaustenr 包提供的文本格式每行为书页里的一行,这个行严格对应着实体书里印刷的行。咱们从这里开始,依旧使用 mutate() 添加 linenumber 批注以记录原始格式里的行数,并且添加 chapter 批注(使用正则表达式)以找到所有的章节位置。
library(janeaustenr)
library(dplyr)
library(stringr)
original_books <- austen_books() %>%
group_by(book) %>%
mutate(linenumber = row_number(),
chapter = cumsum(str_detect(text, regex("^chapter [\\divxlc]",
ignore_case = TRUE)))) %>%
ungroup()
original_books## # A tibble: 73,422 x 4
## text book linenumber chapter
## <chr> <fct> <int> <int>
## 1 "SENSE AND SENSIBILITY" Sense & Sensibility 1 0
## 2 "" Sense & Sensibility 2 0
## 3 "by Jane Austen" Sense & Sensibility 3 0
## 4 "" Sense & Sensibility 4 0
## 5 "(1811)" Sense & Sensibility 5 0
## 6 "" Sense & Sensibility 6 0
## 7 "" Sense & Sensibility 7 0
## 8 "" Sense & Sensibility 8 0
## 9 "" Sense & Sensibility 9 0
## 10 "CHAPTER 1" Sense & Sensibility 10 1
## # ... with 73,412 more rows要把这个当成 tidy 数据集,我们需要重构为每行一个符号的格式,早些时候我们看到可以用 unnest_tokens() 函数完成这个操作。
tidy_books <- original_books %>%
unnest_tokens(word, text)
tidy_books## # A tibble: 725,055 x 4
## book linenumber chapter word
## <fct> <int> <int> <chr>
## 1 Sense & Sensibility 1 0 sense
## 2 Sense & Sensibility 1 0 and
## 3 Sense & Sensibility 1 0 sensibility
## 4 Sense & Sensibility 3 0 by
## 5 Sense & Sensibility 3 0 jane
## 6 Sense & Sensibility 3 0 austen
## 7 Sense & Sensibility 5 0 1811
## 8 Sense & Sensibility 10 1 chapter
## 9 Sense & Sensibility 10 1 1
## 10 Sense & Sensibility 13 1 the
## # ... with 725,045 more rows这个函数使用 tokenizers (Mullen 2018) 包把原始数据框里的每行文本按符号分开。默认按词符号化,而其它选项包括了字符、n元组、句、行、段落,以及正则表达式。
现在数据已经是每行一词的格式,我们可以用 tidy 工具如 dplyr 进行操作了。对于文本分析,我们经常想要移除停止词;停止词是对分析没有帮助的词,典型的停止词包括极度常见的词,如英文里的 “the”、“of”、“to”等等。我们可以用 anti_join() 移除停止词(tidytext 的数据集里存有 stop_words)。
data(stop_words)
tidy_books <- tidy_books %>%
anti_join(stop_words)tidytext 包里的 stop_words 数据集包含有分别来自三个词典的停止词。我们可以一起使用,就像上面这样,或用 filter() 来选择对特定的分析更合适的一个停止词数据集。
我们还可以用 dplyr 的 count() 找出所有书作为一个整体最常见的词。
tidy_books %>%
count(word, sort = TRUE) ## # A tibble: 13,914 x 2
## word n
## <chr> <int>
## 1 miss 1855
## 2 time 1337
## 3 fanny 862
## 4 dear 822
## 5 lady 817
## 6 sir 806
## 7 day 797
## 8 emma 787
## 9 sister 727
## 10 house 699
## # ... with 13,904 more rows因为我们一直在使用 tidy 工具,词的个数存在一个 tidy 数据框里。这让我们可以把它直接通过管道传给 ggplot2 包,例如创建一个最常见的词的可视化(图 1.2)。
tidy_books %>%
count(word, sort = TRUE) %>%
filter(n > 600) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n)) +
geom_col() +
xlab(NULL) +
coord_flip()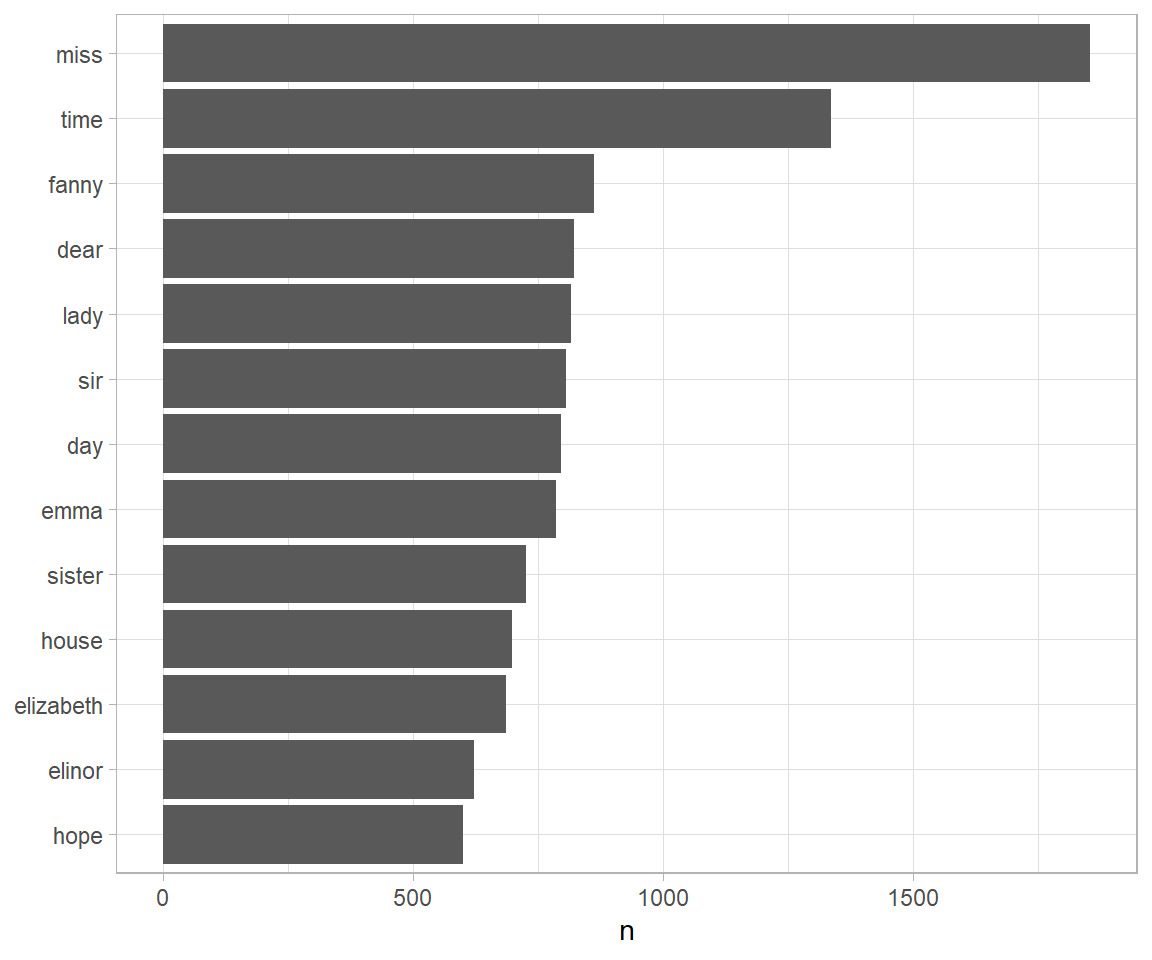
图 1.2: 简·奥斯汀的小说中最常见的词
需要注意的是, austen_books() 函数恰好提供给了我们想要分析的数据,但其它情况下我们可能需要对文本数据进行清洗,比如去除版权信息或重新格式化。在案例分析的章节里将看到这种预处理的例子,特别是章 ??。
1.4 gutenbergr 包
首先介绍一下 gutenbergr 包 (Robinson 2020a)。使用 gutenbergr 包可访问来自古登堡计划的公共领域作品集。包中有下载书籍的工具(且去除了用不上的头部、尾部信息),还有一份完整的古登堡计划数据集元数据,可以用来寻找感兴趣的作品。在这本书中,我们主要使用 gutenberg_download() 函数通过ID从古登堡计划下载一部或多部作品,不过也可使用其它函数来探索元数据,将古登堡ID与作品名、作者、语言等匹配,或是收集有关作者的信息。我们后面要使用的中文作品就是在如下数据中选出的。
library(gutenbergr)
gutenberg_works(languages = "zh")## # A tibble: 386 x 8
## gutenberg_id title author gutenberg_author~ language gutenberg_books~ rights has_text
## <int> <chr> <chr> <int> <chr> <chr> <chr> <lgl>
## 1 4572 粉妝樓1-10~ Luo, Guanz~ 1511 zh <NA> Public do~ TRUE
## 2 4573 粉妝樓11-2~ Luo, Guanz~ 1511 zh <NA> Public do~ TRUE
## 3 4574 粉妝樓21-3~ Luo, Guanz~ 1511 zh <NA> Public do~ TRUE
## 4 4575 粉妝樓31-4~ Luo, Guanz~ 1511 zh <NA> Public do~ TRUE
## 5 4576 粉妝樓41-5~ Luo, Guanz~ 1511 zh <NA> Public do~ TRUE
## 6 4577 粉妝樓51-6~ Luo, Guanz~ 1511 zh <NA> Public do~ TRUE
## 7 4578 粉妝樓61-7~ Luo, Guanz~ 1511 zh <NA> Public do~ TRUE
## 8 4579 粉妝樓71-8~ Luo, Guanz~ 1511 zh <NA> Public do~ TRUE
## 9 4580 粉妝樓 Luo, Guanz~ 1511 zh <NA> Public do~ TRUE
## 10 7209 鬼谷子 Guiguzi, 4~ 2373 zh <NA> Public do~ TRUE
## # ... with 376 more rowsTo learn more about gutenbergr, check out the package’s tutorial at rOpenSci, where it is one of rOpenSci’s packages for data access.
1.5 用 tidy 处理中文大作
笔者整理了一个类似 janeaustenr 的明清小说数据集 mqxsr (Li 2021),我们可以从四大名著的文本开始。
library(mqxsr)
mingqingxiaoshuo <- books()移除过于常见的停止词并分词。注意和第一个例子的区别,这次我们没有保留标点符号(即使保留了也会在下一步被移除)。另外,由于中英文的不同以及包的具体实现有差别,我们直接在分词的阶段就把停止词移除了。
# 不保留标点符号;移除停止词
cutter <- worker(bylines = TRUE, stop_word = "data/stop_word_zh.utf8")
tidy_mingqingxiaoshuo <- mingqingxiaoshuo %>%
mutate(text = sapply(segment(text, cutter), function(x){paste(x, collapse = " ")})) %>%
unnest_tokens(word, text)
tidy_mingqingxiaoshuo## # A tibble: 2,385,929 x 2
## book word
## <fct> <chr>
## 1 水滸傳 楔子
## 2 水滸傳 張天師
## 3 水滸傳 祈
## 4 水滸傳 禳
## 5 水滸傳 瘟疫
## 6 水滸傳 洪
## 7 水滸傳 太尉
## 8 水滸傳 誤
## 9 水滸傳 走
## 10 水滸傳 妖魔
## # ... with 2,385,919 more rows按词频进行排序。
tidy_mingqingxiaoshuo %>%
count(word, sort = TRUE)## # A tibble: 40,368 x 2
## word n
## <chr> <int>
## 1 道 34771
## 2 是 19581
## 3 來 18538
## 4 人 18095
## 5 不 17159
## 6 去 15769
## 7 有 14870
## 8 又 14672
## 9 在 14665
## 10 見 13553
## # ... with 40,358 more rows图 ?? 展示了常见词词频。这里尝试使用 showtext (Qiu and See file AUTHORS for details. 2021) 方便图片里的中文字符正确渲染而无需依赖系统字体。showtext内嵌的文泉驿微米黑是自由字体,遵循GPLv3,允许所有人复制和发布。
library(showtext)
showtext_auto(enable = TRUE)
pdf()
tidy_mingqingxiaoshuo %>%
count(word, sort = TRUE) %>%
filter(n >= 5000) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n)) +
geom_col() +
xlab(NULL) +
coord_flip() +
theme(text = element_text(family = "wqy-microhei"))1.6 词频
文本挖掘中一个通用的任务是察看词频,就像我们前面完成的那样,然后可以在不同的文本间比较词出现的频率。使用 tidy 数据原则,我们可以很自然平滑地完成这个任务。
英文原著用威尔斯(19世纪末二十世纪初)的科幻小说和勃朗特姐妹(十九世纪,活动时间晚于奥斯汀)作品集分别与简·奥斯汀的作品(主要出版于十九世纪一〇年代)进行比较。中文我们可以使用冯梦龙的《三言》和袁枚《子不语》《续子不语》分别与四大名著(均为小说)进行比较。这些作品间的相似程度将如何呢?
使用 gutenberg_download() 和相应的ID获取各个作品,按作家存储。
sanyan <- gutenberg_download(c(24141, 24239, 27582))
zibuyu <- gutenberg_download(c(25245, 25315))简单试一下,看看冯梦龙这些小说里最常用的词是什么。
# 不保留标点符号;移除停止词
cutter <- worker(bylines = TRUE, stop_word = "data/stop_word_zh.utf8")
tidy_sanyan <- sanyan %>%
mutate(text = sapply(segment(text, cutter), function(x){paste(x, collapse = " ")})) %>%
unnest_tokens(word, text)
tidy_sanyan %>%
count(word, sort = TRUE)## # A tibble: 28,185 x 2
## word n
## <chr> <int>
## 1 道 11003
## 2 人 6098
## 3 不 5936
## 4 是 5924
## 5 有 5309
## 6 在 4988
## 7 得 4834
## 8 來 4789
## 9 去 4760
## 10 又 4465
## # ... with 28,175 more rows《子不语》两部依样处理。
# 不保留标点符号;移除停止词
cutter <- worker(bylines = TRUE, stop_word = "data/stop_word_zh.utf8")
tidy_zibuyu <- zibuyu %>%
mutate(text = sapply(segment(text, cutter), function(x){paste(x, collapse = " ")})) %>%
unnest_tokens(word, text)
tidy_zibuyu %>%
count(word, sort = TRUE)## # A tibble: 16,834 x 2
## word n
## <chr> <int>
## 1 曰 3197
## 2 其 3091
## 3 有 2485
## 4 而 2334
## 5 人 2002
## 6 為 1944
## 7 以 1752
## 8 之 1582
## 9 不 1516
## 10 見 1434
## # ... with 16,824 more rows看起来“人”在所有作品里都属于最常见的词,以及意思相当于“说”的词汇(有部分“道”可能是道士的道);《三言》里就只有“道”排在前面,“說”只有其一半左右;《子不语》两部中只有“曰”上榜。这可能是由于文体(文言多用曰)及时代(说对道的替代需要一个过程)的差异。
现在,计算一下每个词在每位作家的作品中出现的频率,把数据框绑定到一起。我们可以使用 tidyr 中的 spread 和 gather 重新定形数据框,只留下绘图需要的点,以便对三个作品集进行比较。
library(tidyr)
frequency <- bind_rows(mutate(tidy_zibuyu, author = "袁枚"),
mutate(tidy_sanyan, author = "冯梦龙"),
mutate(tidy_mingqingxiaoshuo, author = "Various")) %>%
#mutate(word = str_extract(word, "[a-z']+")) %>%
mutate(word = str_extract(word, "[^a-z0-9']+")) %>%
count(author, word) %>%
group_by(author) %>%
mutate(proportion = n / sum(n)) %>%
select(-n) %>%
spread(author, proportion) %>%
gather(author, proportion, `袁枚`:`冯梦龙`)注释掉的行里 str_extract() 的用途是去掉下划线等,因为来自古登堡计划的UTF-8编码文本为了表示强调(斜体)在相应词的前后加了下划线,符号化的时候这些词不应该独立计数。在选用 str_extract() 之前做的初步数据探索中,“_any_”没有算成“any”。对于中文数据集,由于分词方法不同,这一步骤无需使用,相反需要考虑过滤掉英文和数字等,如其下一行代码所示。
现在绘制图 1.3。
library(scales)
# expect a warning about rows with missing values being removed
ggplot(frequency, aes(x = proportion, y = `Various`, color = abs(`Various` - proportion))) +
geom_abline(color = "gray40", lty = 2) +
geom_jitter(alpha = 0.1, size = 2.5, width = 0.3, height = 0.3) +
geom_text(aes(label = word), check_overlap = TRUE, vjust = 1.5, family = "wqy-microhei") +
scale_x_log10(labels = percent_format()) +
scale_y_log10(labels = percent_format()) +
scale_color_gradient(limits = c(0, 0.001), low = "darkslategray4", high = "gray75") +
facet_wrap(~author, ncol = 2) +
theme(legend.position="none") +
labs(y = "Various", x = NULL) +
theme(text = element_text(family = "wqy-microhei"))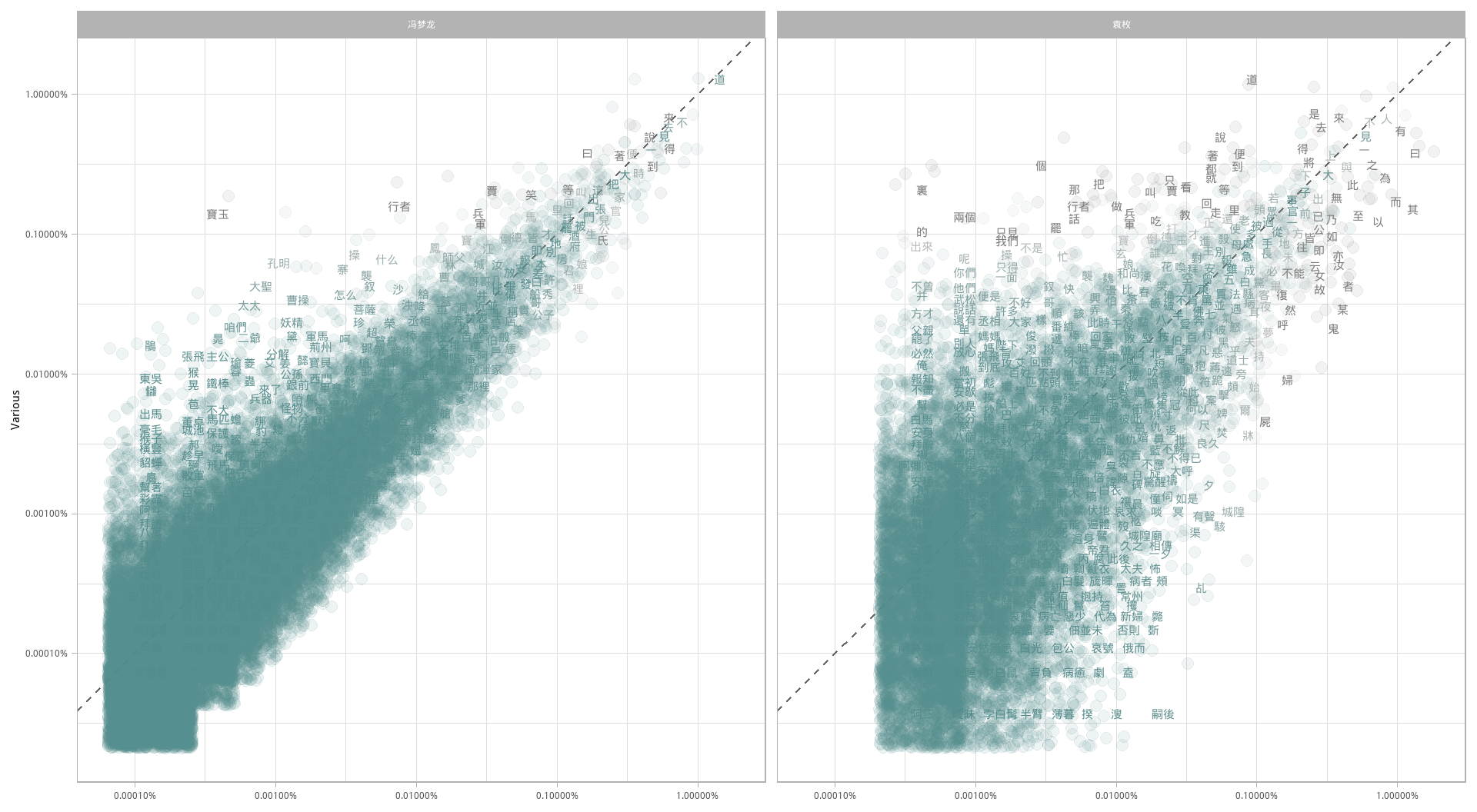
图 1.3: 冯梦龙、袁枚与四大名著的作品词频比较
靠近斜线的点代表的词在相应的两组文本中有着相似的出现频率,比如“道”“是”“不”同时高频出现在四大名著和冯梦龙的文本中,而“不”“見”“上”同时高频出现在四大名著和袁枚的文本中。远离斜线的词在一个文本中比另一个要常见得多。比如,在四大名著-冯梦龙一侧的图中,诸如“寳玉”“大聖”这些词(全是人名和称谓)在四大名著文本中多见,而在冯梦龙文本中就不多,同时“東坡”在冯梦龙文本中更多见而非四大名著文本。
整体来看,注意到在图 1.3 中四大名著-冯梦龙侧比四大名著-袁枚侧更接近过零点的斜线。同时注意四大名著-冯梦龙侧的词向更低频扩展更多;四大名著-袁枚侧在低频词处有片空白区域。这些特征说明四大名著与冯梦龙用词比四大名著与袁枚用词更为接近。还可以看到并非所有词在全部三个文本集中都能找到,四大名著-袁枚侧的数据点偏少。
我们用相关度检验量化一下这些词频集的相似和不同的程度。四大名著与冯梦龙词频的相关度如何?四大名著与袁枚呢?
cor.test(data = frequency[frequency$author == "冯梦龙",], ~ proportion + `Various`)##
## Pearson's product-moment correlation
##
## data: proportion and Various
## t = 622, df = 28156, p-value <2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.9647 0.9662
## sample estimates:
## cor
## 0.9655cor.test(data = frequency[frequency$author == "袁枚",], ~ proportion + `Various`)##
## Pearson's product-moment correlation
##
## data: proportion and Various
## t = 95, df = 14212, p-value <2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.6150 0.6351
## sample estimates:
## cor
## 0.6252与我们在图中所见一致,词频在四大名著和冯梦龙的小说中相关度要高于四大名著和袁枚的随笔中。基本上,这个结论也符合主观的观感。
1.7 小结
在本章中,我们探索了什么叫做将 tidy 数据用于文本,以及 tidy 数据原则如何被应用到自然语言处理中。当文本按照每行一个符号的格式组织的时候,诸如移除停止词或计算词频等任务正是 tidy 工具生态内部熟悉操作的自然应用。每行一个符号的框架可以从单个词扩展到n元组及其它有意义的文本单元,我们在本书中将认识到很多其它类型可供分析时优先选用。